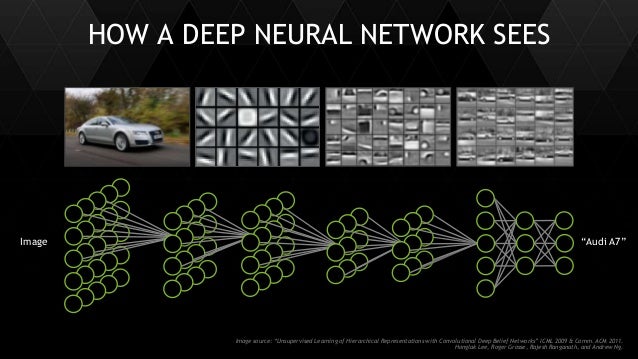
深度學習 (deep learning) 大概是這幾年機器學習領域在應用上大放異彩的主要關鍵之一,從影像、語音到各種資料型態的辨識和分類,藉由深度學習帶來的技術突破,讓電腦達到了接近人類,甚至超越人類的水平。
但是,為什麼深度學習這麼厲害? 目前雖然還沒有完整的解釋,但是 KDNugget 的一篇 "3 Thoughts on Why Deep Learning Works So Well",摘錄了 Yann LeCun (Convolutionl Neural Network 的主要貢獻者之一) 的一些對談,提供了一些可能的思考方向。
七月底,Yann LeCun 在知識網站 Quora 上舉辦了一場線上問答,其中一個問題是「我們什麼時候可以看到深度學習的理論和數學基礎?」(When will we see a theoretical background and mathematical foundation for deep learning?)。
Yann LeCun 的回覆裡有幾個洞見,非常有參考價值:

局部最佳值是在做「數學最佳化」時常常遇見的問題,而大多數機器學習演算法都包含這個步驟,因此也就繼承了同樣的難題,通常需要反覆的調整參數才能克服。深度學習的演算法包含了非常大量的變數,等於是在一個非常高維度的空間裡做最佳化,也因而提供了一個跳脫局部最佳值的途徑。
而 Convolutionl Neural Network 作為深度學習演算法的其中一個分支,在影像辨識,或者更廣義的說,「空間信號」(spatial signals) 上,有比其他型態資料更好的表現,某種程度上也反映出在描述特定資料型態時,有其較適合的數學模型的事實。關於這一點更詳細的解釋,可以在 "Invariant scattering convolution networks" 這篇論文裡找到。
同一個 Quora 問答集裡的另一個問題,聊到深度學習最近值得注意的新發展,Yann LeCun 提到 GAN (Generative Adversarial Networks) 的發展,這跟我過去做過一段時間的 co-evolutionary algorithm 其實是很相近的概念,不過這個話題應該要另外寫一篇了。
Yann LeCun 的回覆裡有幾個洞見,非常有參考價值:
- 在高維度的空間裡,不容易發生局部最佳值 (local minima) 的狀況
- 多層次的數學結構,可以更扼要地描述複雜的函數
- ConvNets 對「特定的資料型態」很有效
局部最佳值是在做「數學最佳化」時常常遇見的問題,而大多數機器學習演算法都包含這個步驟,因此也就繼承了同樣的難題,通常需要反覆的調整參數才能克服。深度學習的演算法包含了非常大量的變數,等於是在一個非常高維度的空間裡做最佳化,也因而提供了一個跳脫局部最佳值的途徑。
而 Convolutionl Neural Network 作為深度學習演算法的其中一個分支,在影像辨識,或者更廣義的說,「空間信號」(spatial signals) 上,有比其他型態資料更好的表現,某種程度上也反映出在描述特定資料型態時,有其較適合的數學模型的事實。關於這一點更詳細的解釋,可以在 "Invariant scattering convolution networks" 這篇論文裡找到。
同一個 Quora 問答集裡的另一個問題,聊到深度學習最近值得注意的新發展,Yann LeCun 提到 GAN (Generative Adversarial Networks) 的發展,這跟我過去做過一段時間的 co-evolutionary algorithm 其實是很相近的概念,不過這個話題應該要另外寫一篇了。